Tutorial 10.4 - Generalized linear models
22 Jul 2018
General linear model
Before discussing generalized linear models, we will first revise a couple of fundamental aspects of general linear models and in particular, how they restrict the usefulness of these models in ecological applications.
General linear models provide a set of well adopted and recognised procedures for relating response variables to a linear combination of one or more continuous or categorical predictors (hence the "general"). Nevertheless, the reliability and applicability of such models are restricted by the degree to which the residuals conform to normality and the mean and variance are independent of one another.
The general linear model essentially comprises three components $$\underbrace{E(Y)}_{Link~~function} = \underbrace{\beta_0 + \beta_1x_1~+~...~+~\beta_px_p}_{Systematic}~~\underbrace{~+~e}_{Random}$$
- The Random (Stochastic) component that specifies the conditional distribution (Normal or Gaussian distribution) of the response variable. Whilst the mean of the normal distribution is assumed to vary as a function of the linear predictors (Systematic component - the regression equation), the variance is assumed to remain constant. Denoted $\epsilon$ in the above equation, the random component is more formally defined as: $$Y_i \sim{} N(\mu_i, \sigma^2)$$ That is, each value of $Y$ (the response) is assumed to be drawn from a normal distribution with different means ($\mu$) yet fixed variance ($\sigma^2$).
- The Systematic component that represents the linear combination of predictors (which can be categorical, continuous, polynomial or other contrasts) for a linear predictor. The linear predictor describes (predict) the "expected" mean and variability of the response(s) (which are assumed to follow normal distribution(s)).
- The Link function which links the expected values of the response (Random component) to the linear combination of predictors (systematic component). For the normal (Gaussian) distribution, the link function is a the "identity" link ($\mu$). That is: $$\mu = \beta_0 + \beta_1x_1~+~...~+~\beta_px_p$$
There are many real situations for which the assumptions imposed by the normal distribution are unlikely to be satisfied. For example, if the measured response to a predictor treatment (such as nest parasite load) can only be binary (such as abandoned or not), then the differences between the observed and expected values (residuals) are unlikely to follow a normal distribution. Instead, in this case, they should follow a binomial distribution.
Often response variables have a restricted range. For example a species may be either present or not present and thus the response is restricted to either 1 (present) or absent (0). Values less than 0 or greater than 1 are not logical. Similarly, the abundance of a species in a quadrat is bounded by a minimum value of zero - it is not possible to have fewer than zero individuals. Proportional abundances are also restricted to between 0 and 1 (or 100). The normal distribution however, is valid for the range between positive and negative infinity (ie not restricted) and thus expected values of the linear predictor can be outside of the restricted range that naturally operates on the response variable. Hence, the normal distribution might not always represent a sensible probability model as it can predict values outside the logical range of the data. Furthermore, the as a result of these range restrictions, variance can be tied to the mean in that expected probabilities towards the extremes of the restricted range tend to have lower variability (as the lower or upper bounds of the probabilities are trunctated).
Data types
Response data can generally be classified into one of four levels
- Nominal - responses are those that represent un-ordered categories For example, we could record the 'preferred' food choice of an animal as either "Fruit", "Meat", "Seeds" or "Leaves". The spacing between categories is undetermined and responses are restricted to those options.
- Ordinal - responses are those that represent categories with sensible orders, yet undetermined spacing between categories. Likert scale questionnaire responses to questions such as "Rate the quality of your experience... on a scale of 1 to 5" are a classic example. Categorized levels of a response ("High", "Medium","Low") would also be another example of an ordinal variable
- Interval - responses are those for which both the order and scale (spacing) are meaningful, yet multiplication is meaningless due to the arbitrary scale of the data (where zero does not refer to nothing). Temperature in degrees C is a good example of such a response (consider whether -28 degrees *-1 = 28 degrees has a sensible interpretation).
- Ratio - responses are those for which order, scale and zero are meaningful. For example a measurement scale such as length in millimeters or mass in grams.
Generalized linear models
Generalized linear models (GLM's) extend the application range of linear modelling by accommodating non-stable variances as well as alternative exponential residual distributions (such as the binomial and Poisson distributions).Generalized linear models have the same three components as general linear models (of which the systematic component is identical), yet a broader range of Random components are accommodated and thus alternative Link functions must also be possible: $$g(\mu) = \beta_0 + \beta_1x_1~+~...~+~\beta_px_p$$
- Random component defines the exponential distribution (Gaussian, Poisson, binomial, gamma, and inverse Gaussian distributions) from which the responses are assumed to be drawn. These distributions are characterised by some function of the mean (canonical or location parameter) and a function of the variance (dispersion parameter). Note that for binomial and Poisson distributions, the dispersion parameter is 1, whereas for the Guassian (normal) distribution the dispersion parameter is the error variance and is assumed to be independent of the mean. The negative binomial distribution can also be treated as an exponential distribution if the dispersion parameter is fixed as a constant.
- Systematic component again defines the linear combination of predictors
- Link function, $g$ links the systematic and random components.
Although there are many commonly employed link functions, typically the exact form of the link function depends
on the nature of the random response distribution.
Some of the canonical (natural choice) link functions and distribution pairings that are suitable for different
forms of generalized linear models are listed in the following table. The only real restriction on a link function
is that it must preserve the order of values such that larger values are always larger than smaller values (be monotonic) and
must yield derivatives that are legal throughout the entire range of the data.
$\mu$ refers to the predicted values of a continuous responseResponse variable Probability distribution Link function Model name Continuous measurements Gaussian identity:
$\mu$Linear regression Binary Binomial logit:
$log\left(\frac{\pi}{1-\pi}\right)$Logistic regression probit:
$\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\alpha+\beta.X} exp\left(-\frac{1}{2}Z^2\right)dZ$Probit regression Complimentary log-log:
$log(-log(1-\pi))$Logistic regression Proportional
(including cover)Binomial logit:
$log\left(\frac{\pi}{1-\pi}\right)$Binomial regression Beta logit:
$log\left(\frac{\pi}{1-\pi}\right)$Beta regression Counts Poisson log:
$log \mu$Poisson regression
log-linear modelNegative binomial $log\left(\frac{\mu}{\mu+\theta}\right)$ Negative biomial regression Quasi-poisson $log\mu$ Poisson regression Survival Gamma $log\mu$ Weibull $log\mu$ Ordinal cumulative cratio, sratio, acat
$\pi$ refers to the predicted values of a binary response
Link functions
In contrast to fitting linear models to transformations of the raw data, the link functions transform the curve predicted by the systematic component into a scale approximating that of the response.
Logit
Log odds-ratio The slope parameter represents the rate of change in log odds-ratio per unit increase in a predictor.Probit
The probit transformation is the inverse cumulative distribution for the standard normal distribution and is useful when the response is likely to be a categorization of an otherwise continuous scale. So whilst measurements might be recorded on a categorical scale (either for convenience or because that is how they manifest), these measurements are a proxy for an underlying variable (latent variable) that is actually continuous. So if the purpose of the linear modeling is to predict the underlying latent variable, then probit regression is likely to be appropriate. The slope parameter represents the rate of change in response probability per unit increase in a predictor.Complementary log-log
The log-log transformation is useful for extremely asymmetrical distributions (notably survival analyses).Negative binomial
Estimation
The generalized nature of GLM's makes them incompatible with ordinary least squares model fitting procedures. Instead, parameter estimates and model fitting are typically achieved by maximum likelihood methods based on an iterative re-weighting algorithm (such as the Newton-Raphson algorithm). Essentially, the Newton-Raphson algorithm (also known as a scoring algorithm) fits a linear model to an adjusted response variable (transformed via the link function) using a set of weights and then iteratively re-fits the model with new sets of weights recalculated according to the fit of the previous iteration. For canonical link-distribution pairs (see the table above), the Newton-Raphson algorithm usually converges (arrives at a common outcome or equilibrium) very efficiently and reliably. The Newton-Raphson algorithm facilitates a unifying model fitting procedure across the family of exponential probability distributions thereby providing a means by which binary and count data can be incorporated into the suit of regular linear model designs. In fact, linear regression (including ANOVA, ANCOVA and other general linear models) can be considered a special form of GLM that features a normal distribution and identity link function and for which the maximum likelihood procedure has an exact solution. Notably, when variance is stable, both maximum likelihood and ordinary least squares yield very similar parameter estimates.
Exponential distributions
Gaussian
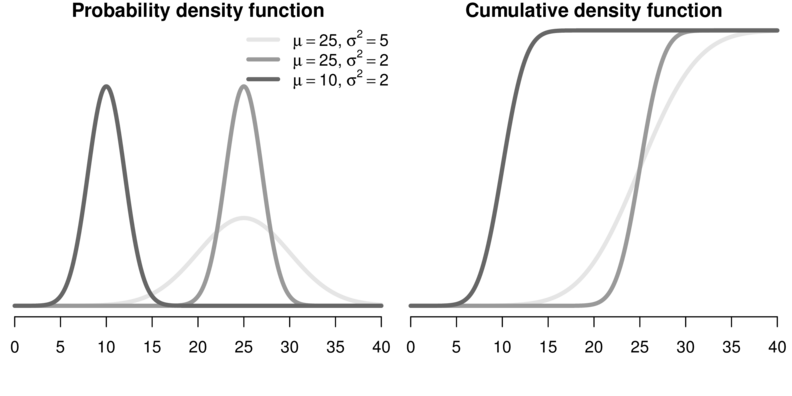
- density function - cummulative distribution
Binomial
Represents the number of successes out of $n$ independent trials each with a set probability (typically 0.5)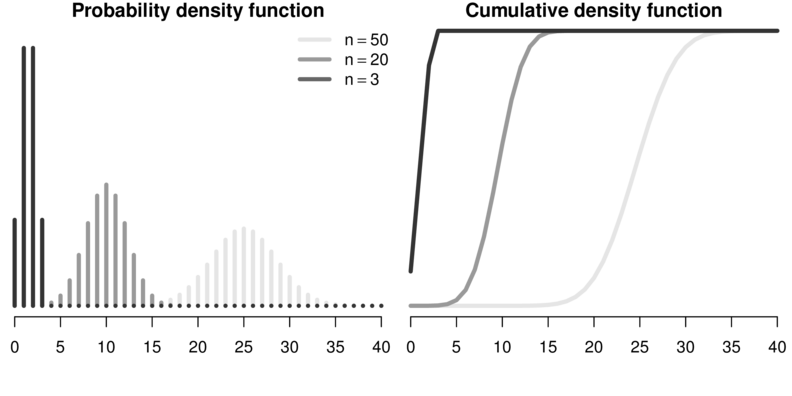
Poisson
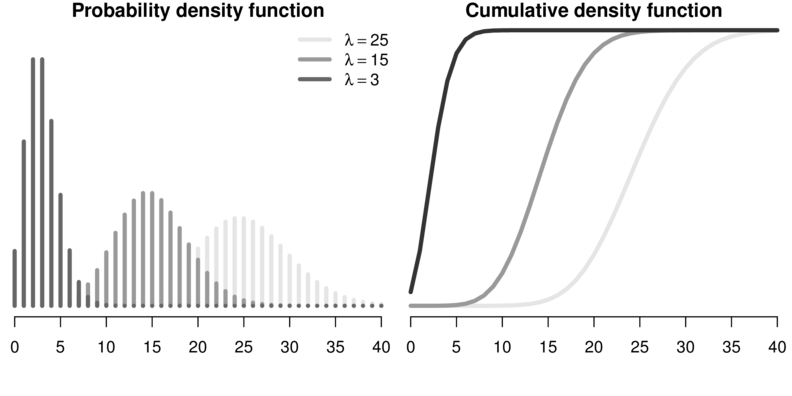
Negative binomial
Represents the number of failures out of a sequence of $n$ independent trials before a success is obtained each with a set probability (typically 0.5)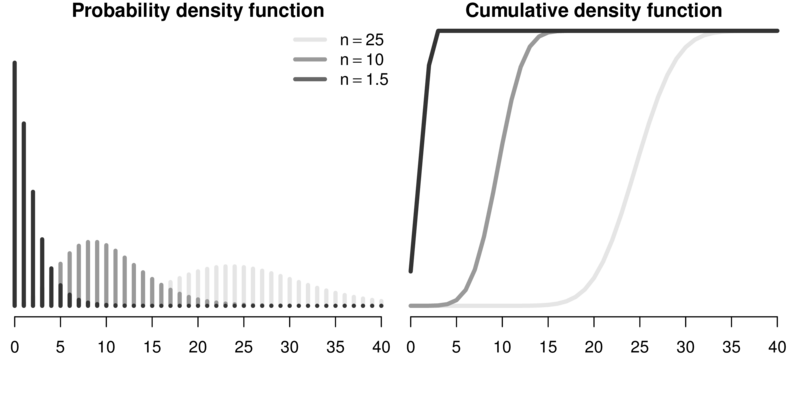
Alternatively, a negative binomial can be defined in terms of its mean ($\mu$) and dispersion parameter. The dispersion parameter can be used to adjust the variances independent of the mean and is therefore useful as an alternative to the Poisson distribution when there is evidence of overdispersion (dispersion parameter >1).
Dispersion
The variance of binomial or Poisson distributions is assumed to be related to the sample size and mean respectively, and thus, there is not a variance parameter in their definitions. In fact, the variance (or dispersion) parameter is fixed to 1. As a result, logistic/probit regression as well as Poisson regression and log-linear modelling assume that sample variances conform to the respective distribution definitions. However, it is common for individual sampling units (e.g. individuals) to co-vary such that other, unmeasured influences, increase (or less commonly, decrease) variability.
For example, although a population sex ratio might be 1:1, male to female ratios within a clutch might be highly skewed towards one or other sex. Positive correlations cause greater variance (overdispersion) and result in deflated standard errors (and thus exaggerated levels of precision and higher Type I errors). Additionally, count data (for example number of fish per transect) can be overdispersed as a result of an unexpectedly high number of zero's (zero inflated). In this case, the zeros arise for two reasons.
- Genuine zero values - zero fish counted because there were non present
- False zeros - there were fish present, yet not detected (and thus not recorded)
The dispersion parameter (degree of variance inflation or over-dispersion) can be estimated by dividing either the Pearsons χ2 or the Deviance () by the degrees of freedom $n−p$, where $n$ is the number of observations in $p$ parameters). As a general rule, dispersion parameters approaching 2 (or 0.5) indicate possible violations of this assumption (although large overdispersion parameters can also be the result of a poorly specified model or outliers). Where over (or under) dispersion is suspected to be an issue, the following options are available:
- use quasibinomial and quasipoisson families can be used as alternatives to model the dispersion. These quasi-likelihood models derive the dispersion parameter (function of the variance) from the observed data and are useful when overdispersion is suspected to be caused by positive correlations or other unobserved sources of variance. Rather than assuming that the variance is fixed, quasi- models assume that variance is a linear (multiplicative) function of the mean. Test statistics from such models should be based on F-tests rather than chi-squared tests.
- for count data, use a negative binomial as an alternative to a Poisson distribution. The negative binomial distribution also estimates the dispersion parameter and assumes that the variance is a quadratic function of the mean.
- use zero-inflated binomial (ZIB) and zero-inflated poisson (ZIP) when overdispersion is suspected to be caused by excessive numbers of zeros.
Binary data - logistic (logit) regression
Logistic regression is a form of GLM that employs the logit-binomial link distribution canonical pairing to model the effects of one or more continuous or categorical (with dummy coding) predictor variables on a binary (dead/alive, presence/absence, etc) response variable. For example, we could investigate the relationship between salinity levels (salt concentration) and mortality of frogs. Similarly, we could model the presence of a species of bird as a function of habitat patch size, or nest predation (predated or not) as a function of the distance from vegetative cover.
Consider the fictitious data presented in the following figure. Clearly, a regular simple linear model (straight line, Figure a) is inappropriate for modelling the probability of presence. Note that at very low and high levels of X, the predicted probabilities (probabilities or proportions of the population) are less than zero and greater than one respectively - logically impossible outcomes. Note also, that the residuals cannot be drawn from a normal distribution, since for any value of X, there are only two possible outcomes (1 or 0).
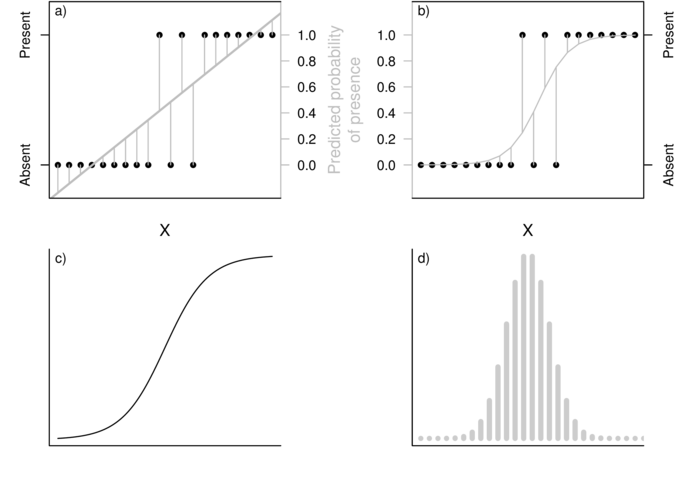
The logistic model (Figure c above) relating the probability ($\pi(x)$) that the response ($y_i$) equals one (present) for a given level of $x_i$ (patch size) is defined as: $$\pi(x) = \frac{e^{\beta_0+\beta_1x}}{1+e^{\beta_0+\beta_1x}}$$
Appropriately, since $e^{\beta_0+\beta_1x}$ (the "natural constant" raised to a simple linear model) must evaluate to between 0 and infinity, the logistic model must asymptote towards (and is thus bounded by) zero and one. Alternatively (as described briefly above), the logit link function: $$ln\left(\frac{\pi(x)}{1-\pi(x)}\right)$$ can be used to transform $\pi(x)$ such that the logistic model is expressed as the log odds (probability of one state relative to the alternative) against a familiar linear combination of the explanatory variables (as is linear regression). $$ln\left(\frac{\pi(x)}{1-\pi(x)}\right)=\beta_0+\beta_1x_i$$
Although the $\beta_0$ (y-intercept) parameter is interpreted similar to that of linear regression (albeit of little biological interest), this is not the case for the slope parameter ($\beta_1$). Rather than representing the rate of change in the response for a given change in the predictor, in logistic regression, $\beta_1$ represents the rate of change in the odds ratio (ratio of odds of an event at two different levels of a predictor) for a given unit change in the predictor. The exponentiated slope represents the odds ratio ($\theta$), the proportional rate at which the predicted odds change for a given unit change of the predictor. $$\theta=e^{\beta_1}$$
Null hypotheses
As with linear regression, a separate H0 is tested for each of the estimated model parameters:
$H_0: \beta_1=0$ (the population slope - proportional rate of change in odds ratio)
This test examines whether the log odds of an occurrence are independent of the predictor variable and thus whether or not there is likely to be a relationship between the response and predictor.
$H_0: \beta_0=0$ (the population intercept equals zero)
As stated previously, this is typically of little biological interest.
Similar to linear regression, there are two ways of testing the main null hypotheses:
- Parameter estimation approach. Maximum likelihood estimates of the parameters and their asymptoticd standard errors ($S_{b_1}$) are used to calculate the Wald $t$ (or $t ratio$) statistic: $$W = \frac{b_1}{S_{b_1}}$$ which approximately follows a standard z distribution when the null hypothesis is true. The reliability of Wald tests diminishes substantially with small sample sizes. For such cases, the second option is therefore more appropriate.
- (log)-likelihood ratio tests approach. This approach essentially involves comparing the fit of models with (full) and without (reduced) the term of interest: \begin{align*} logit(\pi)&=\beta_0+\beta_1x_1 &\mathsf{(full~model)}\\ logit(\pi)&=\beta_0 &\mathsf{(reduced~model)}\\ \end{align*} The fit of any given model is measured via log-likelihood and the differences between the fit of two models is described by a likelihood ratio statistic ($G^2$ = 2(log-likelihood reduced model - log-likelihood full model)). The $G^2$ quantity is also known as deviance and is analogous to the residual sums of squares in a linear model. When the null hypothesis is true, the $G^2$ statistic approximately follows a $\chi^2$ distribution with one degree of freedom. An analogue of the linear model $r^2$ measure can be calculated as: $$r^2=1-\frac{G_0^2}{G_1^2}$$ where $G^2_0$ and $G^2_1$ represent the deviances due to the intercept and slope terms respectively.
Analysis of deviance
Analogous to the ANOVA table that partitions the total variation into components explained by each of the model terms (and the unexplained error), it is possible to construct a analysis of deviance table that partitions the deviance into components explained by each of the model terms.
Count data - Poisson and log-linear models
Another form of data for which scale transformations are often unsuitable or unsuccessful are count data. Count data tend to follow a Poisson distribution (see here) and consequently, the mean and variance are usually related. Generalized linear models provide appropriate means to model count data according to two design contexts:
- as an alternative to linear regression for modeling count data against a linear combination of continuous and/or categorical predictor variables (Poisson regression)
- as an alternative to contingency tables in which the associations between categorical variables are explored (log-linear modelling)
Poisson regression
The Poisson regression model is: $$log(\mu)=\beta_0+\beta_1x_i+...+\beta_px_p$$ where $log(\mu)$ is the link function used to link the mean of the Poisson response variable to the linear combination of predictor variables. Poisson regression otherwise shares null hypotheses, parameter estimation, model fitting and selection with logistic regression.
Log-linear modelling
Contingency tables were introduced in Tutorial 10.1 along with caveats regarding the reliability and interoperability of such analyses (particularly when expected proportions are small or for multi-way tables). In contrast to logistic and Poisson regression, all variables in a log-linear model do not empirically distinguish between response and predictor variables. Nevertheless, as in contingency tables, causality can be implied when logical and justified by interpretation.
Log-linear models
The saturated (or full) log-linear model resembles a multiway ANOVA model. The full and reduced log-linear models for a two factor design are: \begin{align*} log(f_{ij}) &= \mu+\lambda^A_i+\lambda^B_j+\lambda^{AB}_{ij} &\mathsf{(full~model)}\\ log(f_{ij}) &= \mu+\lambda^A_i+\lambda^B_j &\mathsf{(reduced~model)} \end{align*} where $log(f_{ij})$ is the log link function, $\mu$ is the mean of the ($log$) of expected frequencies ($f_{ij}$) and $\lambda^A_i$ is the effect of the ith category of the variable ($A$), $\lambda^B_j$ is the effect of the jth category of $B$ and $\lambda^{AB}_{ij}$ is the interactive effect of each category combination on the ($log$) expected frequencies.
Reduced models differ from full models in the absence of all higher order interaction terms. Comparing the fit of full and reduced models therefore provides a means of assessing the effect of the interaction. Whilst two-way tables contain only a single interaction term (and thus a single full and reduced model), multiway tables have multiple interactions. For example, a three-way table has a three way interaction (ABC) as well as three two-way interactions (AB, AC, BC). Consequently, there are numerous full and reduced models, each appropriate for different interaction terms. The following table indicates the association between null hypothesis and fitted models.
| H0 | Log-linear model | df | $G^2$(reduced-full) | |
|---|---|---|---|---|
| Saturated model | ||||
| 1 | A+B+C+AB+AC+BC+ABC | 0 | ||
| Complete dependence | ||||
| 2 | ABC=0 | A+B+C+AB+AC+BC | (I-1)(J-1)(K-1) | 2-1 |
| Conditional independence | ||||
| 3 | AB=0 | A+B+C+AC+BC | K(I-1)(J-1) | 3-1 |
| 4 | AC=0 | A+B+C+AB+BC | J(I-1)(K-1) | 4-1 |
| 5 | BC=0 | A+B+C+AB+AC | I(J-1)(K-1) | 5-1 |
| Marginal independence | ||||
| 6 | AB=0 | A+B | (I-1)(J-1) | 6-(A+B+AB) |
| 7 | AC=0 | A+C | (I-1)(K-1) | 7-(A+C+AC) |
| 8 | BC=0 | B+C | (J-1)(K-1) | 8-(B+C+BC) |
| Complete independence | ||||
| 9 | AB=AC=BC=0 | A+B+C | 9-2 | |
Null hypotheses
Consistent with contingency table analysis, log-linear models test the null hypothesis (H0) that the categorical variables are independent of (not associated with) one another. Such null hypotheses are tested by comparing the fit (deviance, $G^2$) of full and reduced models. The $G^2$ is compared to a $\chi^2$ distribution with degrees of freedom equal to the difference in degrees of freedom of the full and reduced models. Thereafter, odds ratios are useful for interpreting any lack of independence.
For multi-way tables, there are multiple full and reduced models:
- Complete dependence: H0: ABC = 0. No three way interaction. Either no association (conditional independence) between each pair of variables, or else the patterns of associations (conditional dependencies) are the same for each level of the third. If this null hypothesis is rejected (ABC $\ne$ 0), the causes of lack of independence can be explored by examining the residuals or odds ratios. Alternatively, main effects tests (testing the effects of two-way interactions separately at each level of the third) can be performed. If the three-way interaction is not rejected (no three-way association), lower order interactions can be explored.
- Conditional independence/dependence: if the three-way interaction is not rejected (no three-way association), lower order interactions can be explored.
H0: AB=0 - A and B conditionally independent (not associated) within each level of C.
H0: AC=0 - A and C conditionally independent (not associated) within each level of B.
H0: BC=0 - B and C conditionally independent (not associated) within each level of A.
- Marginal independence:
H0: AB=0 - no association between A and B pooling over C.
H0: AC=0 - no association between A and C pooling over B.
H0: BC=0 - no association between B and C pooling over A.
- Complete independence: If none of the two-way interactions are rejected (no two-way associations), complete independence (all two-way interactions equal zero) can be explored.
H0: AB=AC=BC=0 - Each of the variables are completely independent of all the other variables.
Analysis of designs with more than three factors proceed similarly, starting with tests of higher order interactions and progressing to lower order interactions only in the absence of higher order interactions.
Assumptions
Compared to general linear models, the requirements of generalized linear models are less stringent. In particular, neither normality nor homoscedasticity are assumed. Nevertheless, to maximize the reliability of null hypotheses tests, the following assumptions do apply:
- all observations should be independent to ensure that the samples provide an unbiased estimate of the intended population.
- it is important to establish that no observations are overly influential.
Most linear model influence (and outlier) diagnostics extend to generalized linear models and are taken from the final iteration of the weighted least squares algorithm.
Useful diagnoses include:
- Residuals - there are numerous forms of residuals that have been defined for generalized linear models, each essentially being a variant on the difference between observed and predicted (influence in y-space) theme. Note that the residuals from logistic regression are difficult to interpret.
- Leverage - a measure of outlyingness and influence in x-space.
- Dfbeta - an analogue of Cook’s D statistic which provides a standardized measure of the overall influence of observations on the parameter estimates and model fit.
- although linearity between the response and predictors is not assumed, the relationship between each of the predictors and the link function is assumed to be linear.
This linearity can be examined via the following:
- goodness-of-fit. For log-linear models, $\chi^2$ contingency tables can be performed, however due to the low reliability of such tests with small sample sizes, this is not an option for logistic regression with continuous predictor(s) (since each combination is typically unique and thus the expected values are always 1).
- Hosmer-Lemeshow ($\hat{C}$). Data are aggregated into 10 groups or bins (either by cutting the data according to the predictor range or equal frequencies in each group) such that goodness-of-fit test is more reliable. Nevertheless, the Hosmer-Lemeshow statistic has low power and relies on the somewhat arbitrary bin sizes.
- le Cessie-van Houwelingen-Copas omnibus test. This is a goodness-of-fit test for binary data based on the smoothing of residuals.
- component+residual (partial residual) plots. Non-linearity is diagnosed as a substantial deviation from a linear trend.
- (over or under) dispersion. Section 5 discussed some of the diagnoses and options for dealing with over dispersion