Workshop 7.2a - Nested designs (mixed effects models)
25 Jan 2015
Nested ANOVA references
- Logan (2010) - Chpt 12-14
- Quinn & Keough (2002) - Chpt 9-11
Nested ANOVA - one between factor
In an unusually detailed preparation for an Environmental Effects Statement for a proposed discharge of dairy wastes into the Curdies River, in western Victoria, a team of stream ecologists wanted to describe the basic patterns of variation in a stream invertebrate thought to be sensitive to nutrient enrichment. As an indicator species, they focused on a small flatworm, Dugesia, and started by sampling populations of this worm at a range of scales. They sampled in two seasons, representing different flow regimes of the river - Winter and Summer. Within each season, they sampled three randomly chosen (well, haphazardly, because sites are nearly always chosen to be close to road access) sites. A total of six sites in all were visited, 3 in each season. At each site, they sampled six stones, and counted the number of flatworms on each stone.
Download Curdies data set| Format of curdies.csv data files | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
 |
||||||||||||||||||||||||||||||||||||||||||||
The hierarchical nature of this design can be appreciated when we examine an illustration of the spatial and temporal scale of the measurements.
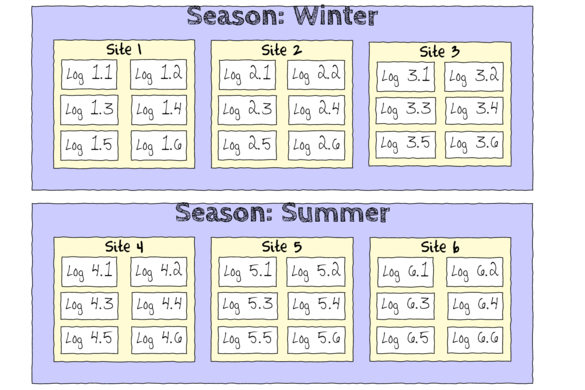
- Within each of the two Seasons, there were three separate Sites (Sites not repeatidly measured across Seasons).
- Within each of the Sites, six logs were selected (haphazardly) from which the number of flatworms were counted.
curdies <- read.table('../downloads/data/curdies.csv', header=T, sep=',', strip.white=T) head(curdies)
SEASON SITE DUGESIA S4DUGES 1 WINTER 1 0.6477 0.8971 2 WINTER 1 6.0962 1.5713 3 WINTER 1 1.3106 1.0700 4 WINTER 1 1.7253 1.1461 5 WINTER 1 1.4594 1.0991 6 WINTER 1 1.0576 1.0141
-
The SITE variable is supposed to represent a random factorial variable (which site).
However, because the contents of this variable are numbers, R initially treats them as numbers, and therefore considers the variable to be numeric rather than categorical.
In order to force R to treat this variable as a factor (categorical) it is necessary to first
convert this numeric variable into a factor (HINT)
.
Show code
curdies$SITE <- as.factor(curdies$SITE)
Notice the data set - each of the nested factors is labelled differently - there can be no replicate for the random (nesting) factor.
- What are the main hypotheses being tested?
- H0 Effect 1:
- H0 Effect 2:
- H0 Effect 1:
- In the table below, list the assumptions of nested ANOVA along with how violations of each assumption are diagnosed and/or the risks of violations are minimized.
Assumption Diagnostic/Risk Minimization I. II. III. - Check these assumptions
(HINT).
Show codeNote that for the effects of SEASON (Factor A in a nested model) there are only three values for each of the two season types. Therefore, boxplots are of limited value! Is there however, any evidence of violations of the assumptions (HINT)?
library(nlme) curdies.ag <- gsummary(curdies,form=~SEASON/SITE, base:::mean) #OR library(plyr) curdies.ag <- ddply(curdies, ~SEASON+SITE, numcolwise(mean))
Show codeboxplot(DUGESIA~SEASON, curdies.ag)
 Show ggplot code(Y or N)
Show ggplot code(Y or N)library(ggplot2) ggplot(curdies.ag, aes(y=DUGESIA, x=SEASON)) + geom_boxplot()

If so, assess whether a transformation will address the violations (HINT) and then make the appropriate correctionsShow codelibrary(plyr) curdies.ag <- ddply(curdies, ~SEASON+SITE, function(x) { data.frame(S4DUGES = mean(x$DUGESIA^0.25, na.rm=TRUE)) }) ggplot(curdies.ag, aes(y=S4DUGES, x=SEASON)) + geom_boxplot()

-
For each of the tests, state which error (or residual) term (state as Mean Square) will be used as the nominator and denominator to calculate the F ratio.
Also include degrees of freedom associated with each term.
Note this is a somewhat outdated procedure as there is far from
consensus about the most appropriate estimate of denominator degrees of freedom. Nevertheless, it sometimes helps to visualize the model hierarchy this way.
Effect Nominator (Mean Sq, df) Denominator (Mean Sq, df) SEASON SITE -
If there is no evidence of violations, fit the model;
S4DUGES = SEASON + SITE + CONSTANT
using a nested ANOVA (HINT). Fill (HINT) out the table below, make sure that you have treated SITE as a random factor when compiling the overall results.Show traditional codecurdies.aov <- aov(S4DUGES~SEASON + Error(SITE), data=curdies) summary(curdies.aov)
Error: SITE Df Sum Sq Mean Sq F value Pr(>F) SEASON 1 5.57 5.57 34.5 0.0042 ** Residuals 4 0.65 0.16 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Error: Within Df Sum Sq Mean Sq F value Pr(>F) Residuals 30 4.56 0.152summary(lm(curdies.aov))
Call: lm(formula = curdies.aov) Residuals: Min 1Q Median 3Q Max -0.381 -0.262 -0.138 0.165 0.902 Coefficients: (1 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 0.3811 0.1591 2.40 0.0230 SEASONWINTER 0.7518 0.2250 3.34 0.0022 SITE2 0.1389 0.2250 0.62 0.5416 SITE3 -0.2651 0.2250 -1.18 0.2480 SITE4 -0.0303 0.2250 -0.13 0.8938 SITE5 -0.2007 0.2250 -0.89 0.3795 SITE6 NA NA NA NA (Intercept) * SEASONWINTER ** SITE2 SITE3 SITE4 SITE5 SITE6 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.39 on 30 degrees of freedom Multiple R-squared: 0.577, Adjusted R-squared: 0.507 F-statistic: 8.19 on 5 and 30 DF, p-value: 5.72e-05library(gmodels) ci(lm(curdies.aov))
Estimate CI lower CI upper (Intercept) 0.3811 0.05622 0.7060 SEASONWINTER 0.7518 0.29235 1.2113 SITE2 0.1389 -0.32055 0.5984 SITE3 -0.2651 -0.72455 0.1944 SITE4 -0.0303 -0.48978 0.4292 SITE5 -0.2007 -0.66013 0.2588 Std. Error p-value (Intercept) 0.1591 0.023031 SEASONWINTER 0.2250 0.002242 SITE2 0.2250 0.541560 SITE3 0.2250 0.247983 SITE4 0.2250 0.893763 SITE5 0.2250 0.379548Show lme codelibrary(nlme) #Fit random intercept model curdies.lme <- lme(S4DUGES~SEASON, random=~1|SITE, data=curdies, method='REML') #Fit random intercept and slope model curdies.lme1 <- lme(S4DUGES~SEASON, random=~SEASON|SITE, data=curdies, method='REML') AIC(curdies.lme, curdies.lme1)
df AIC curdies.lme 4 46.43 curdies.lme1 6 50.11
anova(curdies.lme, curdies.lme1)
Model df AIC BIC logLik Test L.Ratio p-value curdies.lme 1 4 46.43 52.54 -19.21 curdies.lme1 2 6 50.11 59.27 -19.05 1 vs 2 0.3208 0.8518
# Random intercepts and slope model does not fit the data better # Use simpler random intercepts model curdies.lme <- update(curdies.lme, method='REML') summary(curdies.lme)
Linear mixed-effects model fit by REML Data: curdies AIC BIC logLik 46.43 52.54 -19.21 Random effects: Formula: ~1 | SITE (Intercept) Residual StdDev: 0.04009 0.3897 Fixed effects: S4DUGES ~ SEASON Value Std.Error DF t-value p-value (Intercept) 0.3041 0.09472 30 3.211 0.0031 SEASONWINTER 0.7868 0.13395 4 5.873 0.0042 Correlation: (Intr) SEASONWINTER -0.707 Standardized Within-Group Residuals: Min Q1 Med Q3 Max -1.2065 -0.7681 -0.2481 0.3531 2.3209 Number of Observations: 36 Number of Groups: 6#Calculate the confidence interval for the effect size of the main effect of season intervals(curdies.lme)
Approximate 95% confidence intervals Fixed effects: lower est. upper (Intercept) 0.1107 0.3041 0.4976 SEASONWINTER 0.4148 0.7868 1.1587 attr(,"label") [1] "Fixed effects:" Random Effects: Level: SITE lower est. upper sd((Intercept)) 1.875e-07 0.04009 8571 Within-group standard error: lower est. upper 0.3026 0.3897 0.5019#unique(confint(curdies.lme,'SEASONWINTER')[[1]]) #Examine the ANOVA table with Type I (sequential) SS anova(curdies.lme)
numDF denDF F-value p-value (Intercept) 1 30 108.5 <.0001 SEASON 1 4 34.5 0.0042
Show code - lmerlibrary(lme4) # Fit random intercepts model curdies.lmer <- lmer(S4DUGES~SEASON +(1|SITE), data=curdies, REML=TRUE) # Fit random intercepts and slope model curdies.lmer1 <- lmer(S4DUGES~SEASON +(1|SITE), data=curdies, REML=TRUE) AIC(curdies.lmer, curdies.lmer1)
df AIC curdies.lmer 4 46.43 curdies.lmer1 4 46.43
anova(curdies.lmer, curdies.lmer1)
Data: curdies Models: curdies.lmer: S4DUGES ~ SEASON + (1 | SITE) curdies.lmer1: S4DUGES ~ SEASON + (1 | SITE) Df AIC BIC logLik deviance Chisq Chi Df Pr(>Chisq) curdies.lmer 4 40.5 46.9 -16.3 32.5 curdies.lmer1 4 40.5 46.9 -16.3 32.5 0 0 1summary(curdies.lmer)
Linear mixed model fit by REML ['lmerMod'] Formula: S4DUGES ~ SEASON + (1 | SITE) Data: curdies REML criterion at convergence: 38.4 Scaled residuals: Min 1Q Median 3Q Max -1.206 -0.768 -0.248 0.353 2.321 Random effects: Groups Name Variance Std.Dev. SITE (Intercept) 0.00161 0.0401 Residual 0.15185 0.3897 Number of obs: 36, groups: SITE, 6 Fixed effects: Estimate Std. Error t value (Intercept) 0.3041 0.0947 3.21 SEASONWINTER 0.7868 0.1340 5.87 Correlation of Fixed Effects: (Intr) SEASONWINTE -0.707anova(curdies.lmer)
Analysis of Variance Table Df Sum Sq Mean Sq F value SEASON 1 5.24 5.24 34.5#Calculate the confidence interval for the effect size of the main effect of season confint(curdies.lmer)
2.5 % 97.5 % .sig01 0.0000 0.2279 .sigma 0.3067 0.4882 (Intercept) 0.1161 0.4921 SEASONWINTER 0.5344 1.0526
# Perform SAS-like p-value calculations (requires the lmerTest and pbkrtest package) library(lmerTest) curdies.lmer <- lmer(S4DUGES~SEASON +(1|SITE), data=curdies) summary(curdies.lmer)
Linear mixed model fit by REML t-tests use Satterthwaite approximations to degrees of freedom [ merModLmerTest] Formula: S4DUGES ~ SEASON + (1 | SITE) Data: curdies REML criterion at convergence: 38.4 Scaled residuals: Min 1Q Median 3Q Max -1.206 -0.768 -0.248 0.353 2.321 Random effects: Groups Name Variance Std.Dev. SITE (Intercept) 0.00161 0.0401 Residual 0.15185 0.3897 Number of obs: 36, groups: SITE, 6 Fixed effects: Estimate Std. Error df t value Pr(>|t|) (Intercept) 0.3041 0.0947 4.0000 3.21 0.0326 * SEASONWINTER 0.7868 0.1340 4.0000 5.87 0.0042 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Correlation of Fixed Effects: (Intr) SEASONWINTE -0.707anova(curdies.lmer) # Satterthwaite denominator df method
Analysis of Variance Table of type 3 with Satterthwaite approximation for degrees of freedom Sum Sq Mean Sq NumDF DenDF F.value Pr(>F) SEASON 5.24 5.24 1 4 34.5 0.0042 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1anova(curdies.lmer,ddf="Kenward-Roger") # Kenward-Roger denominator df method
Analysis of Variance Table of type 3 with Kenward-Roger approximation for degrees of freedom Sum Sq Mean Sq NumDF DenDF F.value Pr(>F) SEASON 5.24 5.24 1 4 34.5 0.0042 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#Examine the effect season via a likelihood ratio test curdies.lmer1 <- lmer(S4DUGES~SEASON +(1|SITE), data=curdies, REML=F) curdies.lmer2 <- lmer(S4DUGES~1 +(1|SITE), data=curdies, REML=F) anova(curdies.lmer1,curdies.lmer2, test="F")
Data: curdies Models: ..1: S4DUGES ~ 1 + (1 | SITE) object: S4DUGES ~ SEASON + (1 | SITE) Df AIC BIC logLik deviance Chisq Chi Df Pr(>Chisq) ..1 3 51.8 56.6 -22.9 45.8 object 4 40.5 46.9 -16.3 32.5 13.3 1 0.00026 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 - Check the model diagnostics
- Residual plot
Show traditional codepar(mfrow=c(2,2)) plot(lm(curdies.aov))
 Show lme code
Show lme codeplot(curdies.lme)

- For each of the tests, state which error (or residual) term (state as Mean Square) will be used as the nominator and denominator to calculate the F ratio. Also include degrees of freedom associated with each term.
Source of variation df Mean Sq F-ratio P-value SEASON SITE Residuals
Estimate Mean Lower 95% CI Upper 95% CI Summer Effect size (Winter-Summer)