Tutorial 12.9 - Integrated Nested Laplace Approximation (INLA)
20 Feb 2016
Overview
Tutorials 4.2, 4.3 and 7.2b introduced and at times promoted the Bayesian framework for statistical modelling. Indeed, most of the Tutorials were presented as a parallel series of Frequentist and Bayesian tutorials.
Bayesian inference was summarised as the posterior probability of a hypothesis (probability of parameters given data) being equal to the likelihood (probability of data given parameters/hypothesis) multiplied by the prior probability (prior belief in parameters) all normalized (divided by something such that the area under the curve is 1) by division with the probability of the data integrated across all possible levels of the parameters. $$ p(\theta|y) = \frac{p(y|\theta)p(\theta)}{\int{}p(y|\theta)p(\theta)d\theta} $$
However, until the advent of simulation-based techniques (such as Marchov Chain Monte Carlo or MCMC) sampling, the inability to calculate the normalizing constant for anything but the most trivial of situations severely limited the application of these techniques. Furthermore, dedicated software developments (such as WinBUGS, JAGS and STAN) in addition to MCMC sampling extensions within numerous other environments (such as R, python and matlab) have facilitated a rapid growth in the popularity, application and development of Bayesian techniques to any conceivable model.
To some extent, whereas frequentist inferences are built mathematical elegance (with increasing complexity to deal with designs of higher complexity), practical Bayesian methods are just a matter of pure computational grunt. Given enough iterations, any model can be fully estimated exactly.
Whilst MCMC can theoretically provide exact inference, despite considerable advancements in MCMC samplers that achieve substantial improvements in chain mixing and convergence, unfortunately in practice, satisfactory mixing and convergence still necessitates very large iterations that can take a long time to collect. For large data sets and/or complex likelihoods and hierarchical designs, this time can be prohibitively large to be practical. The long runtimes tend also to mean that alternative models are not explore. Hence recent developments have begun exploring Bayesian approximation techniques that yield equivalent (accurate) outcomes in a fraction of the time.
In order to achieve an approximate inference, certain restrictions and assumptions are introduced. Firstly, rather than being a solution applicable to any model (as is the MCMC case), approximate inference techniques focus on a restricted range of models (called structured additive regression models). This specific (yet very broad) family of models are generally those with statistical acronyms beginning with 'G' and ending with 'M' (such as GLM, GLMM, GAM, GAMM). And secondly, if we assume that probability distributions behave like standard distributions (such as the Gaussian distribution), then they can be approximated from a smaller set of properties (such as location and spread).
One of these development areas is Integrated Nested Laplace Approximation (INLA). INLA models are built on the following concepts:
- Latent Gaussian models
- Gaussian Markov Random Fields (GMRF)
- Laplace Approximation
Latent Gaussian models
In a structured additive regression model, the response ($y$) is assumed to be distributed according to an exponential family (such as Gaussian, Poisson, Binomial, Negative Binomial, Gamma etc) and the expected value of the response ($\mu$) is linked to structured linear predictor ($\eta$) via a link function ($g(\mu) = \eta$). It is considered additive as the different structured components (associated with the covariates) are assumed to accrue to the linear predictor additively.
Familiar formulations of a structured additive regression model include:
- classical multiple regression (including ANOVA) models
$$
\mu_i = E(y_i) = \underbrace{\alpha + \sum^p_{j=1}{\beta_jx_{ij}}}_{\text{fixed effects}} + \varepsilon_i, \hspace{3em}i = 1,....,n
$$
where:
- $\mu_i$ are the expected values of the $i$ observations
- $\alpha$ is the intercept
- $x_{ij}$ are the ($i$th level of the $j$th covariate) $p$ covariates
- $\beta$ are the $p$ linear effects parameters
- $\varepsilon_i$ are the residuals
- Generalized linear models (GLM)
$$
\eta_i = g(\mu_i) = \underbrace{\alpha + \sum^p_{j=1}{\beta_jx_{ij}}}_{\text{fixed effects}} + \varepsilon_i, \hspace{3em}i = 1,....,n
$$
where:
- $\eta_i$ is the linear predictor
- $g(.)$ is the link function
- $\mu_i$ are the expected values of the $i$ observations
- $\alpha$ is the intercept
- $x_{ij}$ are the ($i$th level of the $j$th covariate) $p$ covariates
- $\beta$ are the $p$ linear effect parameters
- $\varepsilon_i$ are the residuals
- Generalized additive models (GAM)
$$
\eta_i = g(\mu_i) = \alpha + \underbrace{\sum^q_{k=1}{f_k(c_{ik})}}_{\text{smooth effects}} + \varepsilon_i, \hspace{3em}i = 1,....,n
$$
where:
- $\eta_i$ is the linear predictor
- $g(.)$ is the link function
- $\mu_i$ are the expected values of the $i$ observations
- $\alpha$ is the intercept
- $c_{ij}$ are the ($i$th level of the $k$th covariate) $q$ covariates
- $f_k(.)$ are the $q$ non-linear smooth effect functions
- $\varepsilon_i$ are the residuals
- Generalized linear mixed effects models (GLMM)
$$
\eta_i = g(\mu_i) = \underbrace{\alpha + \sum^p_{j=1}{\beta_jx_{ij}}}_{\text{fixed effects}} + \underbrace{\sum^r_{l=1}{\gamma_l(z_{il})}}_{\text{random effects}} + \varepsilon_i, \hspace{3em}i = 1,....,n
$$
where:
- $\eta_i$ is the linear predictor
- $g(.)$ is the link function
- $\mu_i$ are the expected values of the $i$ observations
- $\alpha$ is the intercept
- $x_{ij}$ are the ($i$th level of the $j$th covariate) $p$ covariates
- $\beta$ are the $p$ linear effect parameters
- $z_{il}$ are the ($i$th level of the $l$th i.i.d random effect) $r$ structured random effects
- $\gamma_l$ are the $r$ structured random effects
- $\varepsilon_i$ are the residuals (unstructured random effects)
- Generalized (additive) (mixed effects) models (GLM, GAM, GLMM, GAMM)
$$
\eta_i = g(\mu_i) = \underbrace{\alpha + \sum^p_{j=1}{\beta_jx_{ij}}}_{\text{fixed effects}} + \underbrace{\sum^q_{k=1}{f_k(c_{ik})}}_{\text{smooth effects}} + \underbrace{\sum^r_{l=1}{\gamma_l(z_{il})}}_{\text{random effects}} + \varepsilon_i, \hspace{3em}i = 1,....,n
$$
where:
- $\eta_i$ is the linear predictor
- $g(.)$ is the link function
- $\mu_i$ are the expected values of the $i$ observations
- $\alpha$ is the intercept
- $x_{ij}$ are the ($i$th level of the $j$th covariate) $p$ covariates
- $\beta$ are the $p$ linear effect parameters
- $c_{ij}$ are the ($i$th level of the $j$th covariate) $q$ covariates
- $f_k(.)$ are the $q$ non-linear smooth effect functions
- $z_{il}$ are the ($i$th level of the $l$th i.i.d random effect) $r$ structured random effects
- $\gamma_l$ are the $r$ structured random effects
- $\varepsilon_i$ are the residuals
The Latent model thus estimates the set of parameters $\theta$ = {$\eta$, $\alpha$, $\beta$, $f_k(.)$, $\gamma$}. The flexibility of this model lies in the generality of the functions $f_k(.)$ which can include splines as well as spatially and temporally indexed covariates. If we assume that each of the parameters are Gaussian (not an unreasonable assumption in most situations), then the model is considered a Latent Gaussian model and if jointly assumed to be drawn from a multivariate normal distribution, then it is considered a Gaussian Latent Field. $$ \theta \sim{} N(., \Sigma) $$ where $\Sigma$ is the variance covariance matrix, the off diagonals of which (covariances) are typically (for models that assume independence) non-zero as many parameters are related in some manner. $$ \Sigma = \begin{pmatrix} \sigma^2 & 0 & 0 & \cdots\\ 0 & \sigma^2 & 0 & \cdots\\ 0 & 0 & \sigma^2 & \cdots\\ \vdots & \vdots & \vdots & \ddots \end{pmatrix} $$
However, there are numerous situations (such as when incorporating temporal or spatial autocorrelation, or random effects dependency structures) when the
off diagonals are not all zero and instead represent the pattern of dependency between observations or parameters.
For example, when incorporating a first order autoregressive structure (AR1) in a single variable, the value of the off diagonals is assumed to be some correlation ($\rho$)
raised to a power that increases with increasing separation between observations.
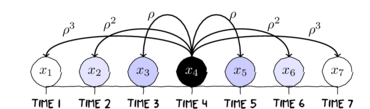 $
\Sigma = \begin{pmatrix}
\sigma^2 & \rho & \rho^2 & \rho^3 & \cdots\\
\rho & \sigma^2 & \rho & \rho^2 & \cdots\\
\rho^2 & \rho & \sigma^2 & \rho & \cdots\\
\rho^3 & \rho^2 & \rho & \sigma^2 & \cdots\\
\vdots & \vdots & \vdots & \vdots & \ddots
\end{pmatrix}
$
$
\Sigma = \begin{pmatrix}
\sigma^2 & \rho & \rho^2 & \rho^3 & \cdots\\
\rho & \sigma^2 & \rho & \rho^2 & \cdots\\
\rho^2 & \rho & \sigma^2 & \rho & \cdots\\
\rho^3 & \rho^2 & \rho & \sigma^2 & \cdots\\
\vdots & \vdots & \vdots & \vdots & \ddots
\end{pmatrix}
$
It should be reasonably obvious that an increase in the number of times ($n$) results in an exponential ($n^2$) increase in covariances and this covariance matrix can soon become very large. Standard variance calculations involve multiplying the variance-covariance matrix by an inverse of the variance-covariance matrix. However, calculating the inverse of a variance-covariance matrix requires a substantial expansion of the matrix dimensions that can rapidly exhaust all available memory. This problem is also encountered for the covariance matrix of a Gaussian Latent Field (as the number of parameters increases, so to does the size of $\Sigma$) - particularly if there are numerous or complex spatial smoothing functions ($f_k(.)$).
Gaussian Markov Random Fields (GMRF)
A process (such as that that determines the realizations of a parameter) is considered to have Markov properties if the expected future state of a parameter depends only on the current state and not on the state prior to the current. That is the expected state depends only on the directly adjacent state. Hence the future state is conditionally independent - it is independent conditioned only on the immediately adjacent state (depend only on immediate neighbours). If we then extend this to multiple parameters (for example, multiple random effects), then it is said to be a Markov Random Field.
By way of temporal autocorrelation again, the dependency umongst times would be considered Markov if the expected value at a particular time
was only dependent on the values immediately adjacent (for example, $x_4$ depends only on $x_3$ and $x_5$).
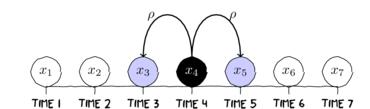 $
\Sigma = \begin{pmatrix}
\sigma^2 & \rho & \rho^2 & \rho^3 & \cdots\\
\rho & \sigma^2 & \rho & \rho^2 & \cdots\\
\rho^2 & \rho & \sigma^2 & \rho & \cdots\\
\rho^3 & \rho^2 & \rho & \sigma^2 & \cdots\\
\vdots & \vdots & \vdots & \vdots & \ddots
\end{pmatrix}
$
$
\Sigma = \begin{pmatrix}
\sigma^2 & \rho & \rho^2 & \rho^3 & \cdots\\
\rho & \sigma^2 & \rho & \rho^2 & \cdots\\
\rho^2 & \rho & \sigma^2 & \rho & \cdots\\
\rho^3 & \rho^2 & \rho & \sigma^2 & \cdots\\
\vdots & \vdots & \vdots & \vdots & \ddots
\end{pmatrix}
$
Sparse matrix
$$
\textbf{Q} = \Sigma^{-1} = \begin{pmatrix}
\sigma^2 & \rho & & &\\
\rho & \sigma^2 & \rho & &\\
& \rho & \sigma^2 & \rho &\\
& & \rho & \sigma^2 & \cdots\\
& & & \vdots & \ddots
\end{pmatrix}
$$
Sigma <- matrix(c(0.83,0.67,0.5,0.33,0.17, 0.67, 1.33, 1, 0.67, 0.33, 0.5, 1, 1.5, 1, 0.5, 0.33, 0.67, 1, 1.33, 0.67, 0.17, 0.33, 0.5, 0.67, 0.83), nrow=5) times <- 1:5 rho<-0.5 sigma <- 1.5 H <- abs(outer(times, times, "-")) Sigma <- sigma * rho^H p <- nrow(Sigma) Sigma[cbind(1:p, 1:p)] <- Sigma[cbind(1:p, 1:p)] * sigma Sigma
[,1] [,2] [,3] [,4] [,5] [1,] 2.25000 0.7500 0.375 0.1875 0.09375 [2,] 0.75000 2.2500 0.750 0.3750 0.18750 [3,] 0.37500 0.7500 2.250 0.7500 0.37500 [4,] 0.18750 0.3750 0.750 2.2500 0.75000 [5,] 0.09375 0.1875 0.375 0.7500 2.25000
Q<-solve(Sigma) Q
[,1] [,2] [,3]
[1,] 0.502032732 -0.156503006 -0.02946593
[2,] -0.156503006 0.550818305 -0.14732965
[3,] -0.029465930 -0.147329650 0.55248619
[4,] -0.005559609 -0.027798047 -0.14732965
[5,] -0.001111922 -0.005559609 -0.02946593
[,4] [,5]
[1,] -0.005559609 -0.001111922
[2,] -0.027798047 -0.005559609
[3,] -0.147329650 -0.029465930
[4,] 0.550818305 -0.156503006
[5,] -0.156503006 0.502032732
The parameters of the linear predictor (those parameters that do not include variance, overdispersion, correlation etc - hyperparameters) are assumed to be drawn from normal (Gaussian) distributions. The set of these parameters are called a Latent Field and if the parameters of a Latent Field are all and jointly assumed to be drawn from a multivariate normal distribution, then it is considered a Gaussian Latent Field. Finally, if the Gaussian Latent Field is assumed to have Markov properties, then it is referred to as a Gaussian Markov Random Field.
So, a Latent Field can be approximated by a Gaussian Markov Random Field: $$ \theta = \{\eta, \alpha, \beta, f_k(.), \gamma\} \sim{} GMRF(\psi) $$ where:
- $\theta$ denotes the set of parameters (Latent Field)
- $\alpha$ the intercept parameter (as in regular linear models)
- $\beta$ the linear predictor effect parameters (as in regular linear models)
- $f_k$ the set of $k$ functions associated with non-linear covariates (as in GAM smoothers)
- $\psi$ are hyper-parameters representing the covariance matrix $\Sigma$
Since the covariance matrix ($\Sigma$) as it is very dense (each cell as a value), it is very intense to work with. Conversely, under conditional independence (the Markov property), the inverse of the covariance matrix, called the precision matrix ($Q = \Sigma^{-1}$) contains a large number of zeros (is very sparse) are much simpler.
If Gaussian Markov Random Fields can be assumed, then estimations are computationally efficient.
If we assume that the parameters are described by a Gaussian Markov Random Field,, then the model is referred to as a Latent Gaussian model.Laplace Approximation
Gelman (2006)
R-INLA
library(R2jags) library(INLA) library(ggplot2)
In providing a first experience with an implementation of any statistic, it is always difficult to know how simple of complex an example to use. On the one hand, a very simple model (such as a linear regression) is attractive as most people have experience with these models and will therefore will readily be able to place the output in the context of something they are already familiar with (and can even then directly compare the output to the output they are used to). On the other hand, overly simple examples lack some of the important aspects that are necessary to obtain a basic understanding of the INLA interface and output.
With this balance in mind, I have elected to start with a relatively simple randomized block (mixed effects model) with Poisson distributed response. The next tutorial (Tutorial 12.10) will then focus on illustrating INLA for a series of linear models from simple regression through to factorial ANOVA. Tutorials 12.11, 12.12 and 12.13 will respectively showcase linear mixed effects models (LMM), generalized linear models (GLM), generalized linear mixed effects (GLMM) and generalized additive (mixed) models (GAMM). Finally, Tutorials 12.14 will introduce spatial and spatio-temporal models in INLA.
As a motivating example, consider an experimental design in which we wish to measure of the abundance of individuals of a species (or number of incidents etc) in response to some continuous influence (such as level of temperature). In an attempt to minimize the expected extent of unexplained variability (due to highly heterogeneous underlying conditions across the landscape), the full range of covariate was applied in each block (a relatively small spatial scale). In all, we will employ 20 randomly (or haphazardly selected) sites and the treatments will be applied randomly (or haphazardly) within sites.
- the number of sites ($sites$) = 20
- the categorical treatment $treat$ variable comprising of three levels ('High', 'Medium' and 'Low')
- the mean value of $y$ of the 'low' treatment is 10
- the standard deviation in 'low' treatment $y$ values across the 20 sites is 5
- the mean effect of the 'Medium' effect is -2
- the mean effect of the 'High' effect is -4
- to generate the values of $y$ expected at each $treat$ level within each of the $sites$, we evaluate the linear predictor (created by calculating the outer product of the model matrix and the regression parameters). These expected values are then transformed into a scale mapped by (0,$\infty$) by using the log function $e^{linear~predictor}$
- finally, we generate $y$ values by using the expected $y$ values ($\lambda$) as probabilities when drawing random numbers from a Poisson distribution. This step adds random noise to the expected $y$ values and returns only 0's and positive integers.
set.seed(5) #3 #7 #number of sites n.sites <- 20 n.x <- 10 dat<-data.frame(Sites=gl(n=n.sites, k=n.x, lab=paste("Site",1:n.sites,sep='')), x=as.vector(replicate(n.sites,sort(runif(n = n.x, min = 1, max =20))))) Xmat <- model.matrix(~-1+Sites+x, data=dat) intercept.mean <- 0.5 intercept.sd <- 0.2 slope<-0.2 linpred <- Xmat %*% c(rnorm(n.sites,intercept.mean, intercept.sd),slope) #Predicted y values lambda <- exp(linpred) #Add some noise and make binomial y <- rpois(n=n.sites*n.x, lambda=lambda) dat <- data.frame(y,dat) ggplot(dat, aes(y=y, x=x)) + geom_point() + facet_wrap(~Sites)

ggplot(dat, aes(y=y, x=1)) + geom_boxplot() + facet_wrap(~Sites)

library(lme4) summary(dat.glmm<-glmer(y~x+(1|Sites), dat, family='poisson'))
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [glmerMod
]
Family: poisson ( log )
Formula: y ~ x + (1 | Sites)
Data: dat
AIC BIC logLik deviance df.resid
1146.5 1156.4 -570.3 1140.5 197
Scaled residuals:
Min 1Q Median 3Q Max
-2.85568 -0.61379 -0.05303 0.59470 2.69435
Random effects:
Groups Name Variance Std.Dev.
Sites (Intercept) 0.0451 0.2124
Number of obs: 200, groups: Sites, 20
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.515284 0.077191 6.68 2.46e-11 ***
x 0.198939 0.003913 50.85 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
x -0.763
convergence code: 0
Model failed to converge with max|grad| = 0.00167027 (tol = 0.001, component 1)
library(effects) plot(allEffects(dat.glmm, partial.resid=TRUE), type='response')

$$ \begin{align} y_i&\sim{}\mathcal{Pois}(\eta_i)\\ log(\eta_i) &= \alpha + \beta X_{i} + \sum_{j=1}^J{}\gamma_{ij}\mathbf{Z_i} + \varepsilon_i \end{align} $$
Before we begin, there are a couple of differences between INLA and more conventional analyses that require brief explanation in order to avoid excessive confusion.
- there is no predict() function associated with INLA. Instead, predictions are performed one of two ways:
- appending prediction cases onto the input data (with NA values for the response). The responses will then be imputed (predicted) as part of the linear predictor (link scale) and fitted values (response scale)
- providing a (modified) model matrix as a linear combination. Linear combinations also provide a means of performing any other contrasts and can be generated on both the link scale and the response scale
- structured random effects (such as smoothers, and spatial effects) are defined via the f() function.
- all parameters and hyperparameters have associated priors.
- fixed parameters have weakly informative Gaussian (normal) priors (mean=0, precision=0.00005)
- structured random parameters have weakly informative Gaussian (normal) priors (mean=0, precision=0.00005)
- hyper-parameters have logGamma priors (mean=1, precision=0.01)
Prior Default parameters Control Gaussian Intercept:
X:N(0,0)
N(0,0.001)control.fixed=list(mean.intercept=0, prec.intercept=0, mean=0, prec=0.001) logGamma Intercept:
X:N(0,0)
N(0,0.001)control.fixed=list(mean.intercept=0, prec.intercept=0, mean=0, prec=0.001)
To fully appreciate the INLA interface, the first model we fit will incorporate many more features and options than is usually necessary. For example, we will specify:
- priors for all fixed, random and hyper-parameters
formula <- y~x+f(Sites, model='iid') dat.inla <- inla(formula, data=dat, family='poisson') summary(dat.inla)
Call:
"inla(formula = formula, family = \"poisson\", data = dat)"
Time used:
Pre-processing Running inla Post-processing Total
0.1268 0.0385 0.0250 0.1904
Fixed effects:
mean sd 0.025quant 0.5quant 0.975quant mode kld
(Intercept) 0.5161 0.0769 0.3639 0.5165 0.6661 0.5173 0
x 0.1989 0.0039 0.1913 0.1989 0.2066 0.1988 0
Random effects:
Name Model
Sites IID model
Model hyperparameters:
mean sd 0.025quant 0.5quant 0.975quant mode
Precision for Sites 24.22 8.504 11.30 23.02 44.28 20.74
Expected number of effective parameters(std dev): 19.12(0.4672)
Number of equivalent replicates : 10.46
Marginal log-Likelihood: -588.27
dat.inla$all.hyper
$predictor $predictor$hyper $predictor$hyper$theta $predictor$hyper$theta$name [1] "log precision" attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$short.name [1] "prec" attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$initial [1] 11 attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$fixed [1] TRUE attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$prior [1] "loggamma" attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$param [1] 1e+00 1e-05 attr(,"inla.read.only") [1] FALSE $predictor$hyper$theta$to.theta function (x) log(x) <bytecode: 0xd966610> <environment: 0xd966488> attr(,"inla.read.only") [1] TRUE $predictor$hyper$theta$from.theta function (x) exp(x) <bytecode: 0xd966530> <environment: 0xd966488> attr(,"inla.read.only") [1] TRUE $family $family[[1]] $family[[1]]$label [1] "poisson" $family[[1]]$hyper list() $family[[1]]$link $family[[1]]$link$hyper list() $fixed $fixed[[1]] $fixed[[1]]$label [1] "(Intercept)" $fixed[[1]]$prior.mean [1] 0 $fixed[[1]]$prior.prec [1] 0 $fixed[[2]] $fixed[[2]]$label [1] "x" $fixed[[2]]$prior.mean [1] 0 $fixed[[2]]$prior.prec [1] 0.001 $random $random[[1]] $random[[1]]$label [1] "Sites" $random[[1]]$hyper $random[[1]]$hyper$theta $random[[1]]$hyper$theta$name [1] "log precision" attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$short.name [1] "prec" attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$prior [1] "loggamma" attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$param [1] 1e+00 5e-05 attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$initial [1] 4 attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$fixed [1] FALSE attr(,"inla.read.only") [1] FALSE $random[[1]]$hyper$theta$to.theta function (x) log(x) <bytecode: 0xd832920> <environment: 0xd85e000> attr(,"inla.read.only") [1] TRUE $random[[1]]$hyper$theta$from.theta function (x) exp(x) <bytecode: 0xd832840> <environment: 0xd85e000> attr(,"inla.read.only") [1] TRUE
References
[1] A. Gelman. "Prior distributions for variance parameters in hierarchical models". In: _Bayesian Analysis_ (2006), pp. 515-533.